Forudsigelser med matematik: Poisson model til fodboldmål 2026
- Historisk matematik i betting: Poisson-modellens indflydelse på målestimationer
- Poisson i én sætning — og hvorfor fodbold er et næsten perfekt match
- Angrebs- og forsvarsstyrke — byggeklodserne i din model
- Beregning af en Superliga-kamp — skridt for skridt
- Svaghederne ved modellen — det den ikke kan se
- Hvornår modellen virkelig tjener sin plads
Historisk matematik i betting: Poisson-modellens indflydelse på målestimationer
Første gang jeg byggede en Poisson-model, var jeg studerende, og jeg lavede den i Excel på et køkkenbord. Modellen forudsagde 2,3 mål for hjemmeholdet og 1,1 for gæsterne. Kampen endte 2-1. Jeg syntes, jeg havde opfundet guld. Et halvt år senere lavede den samme model en forudsigelse på 1,8-0,9 i en kamp, der endte 4-4. Jeg lærte den dag, at modellen ikke forudsiger kampe. Den modellerer dem — og forskellen er afgørende.
Siméon Denis Poisson døde i 1840 og anede ikke, at hans fordeling ville ende med at være rygraden i fodbold-statistik. Men fordelingen beskriver en bestemt slags hændelser usædvanligt godt: sjældne, uafhængige, tilfældigt fordelte begivenheder, hvor vi kender det gennemsnitlige antal. Fodboldmål er netop sådan en ting — i de fleste kampe. Ikke perfekt, men tilstrækkeligt til, at en model baseret på Poisson kan give dig et solidt regnestykke for, hvor sandsynligt 0-0, 1-0, 2-1 eller 3-3 er i en given kamp.
Denne guide går fra grundprincippet og hele vejen til en konkret beregning af en Superliga-kamp. Jeg forudsætter ikke matematisk baggrund, men du skal være villig til at slå til med en lommeregner eller et regneark. Belønningen er, at du fra dag til dag vil kunne tage en favoritkamp og sige, om 2,5-mål-linjen er fair, billig eller dyr — uden at være afhængig af, hvad bookmakerne tror.
Poisson i én sætning — og hvorfor fodbold er et næsten perfekt match
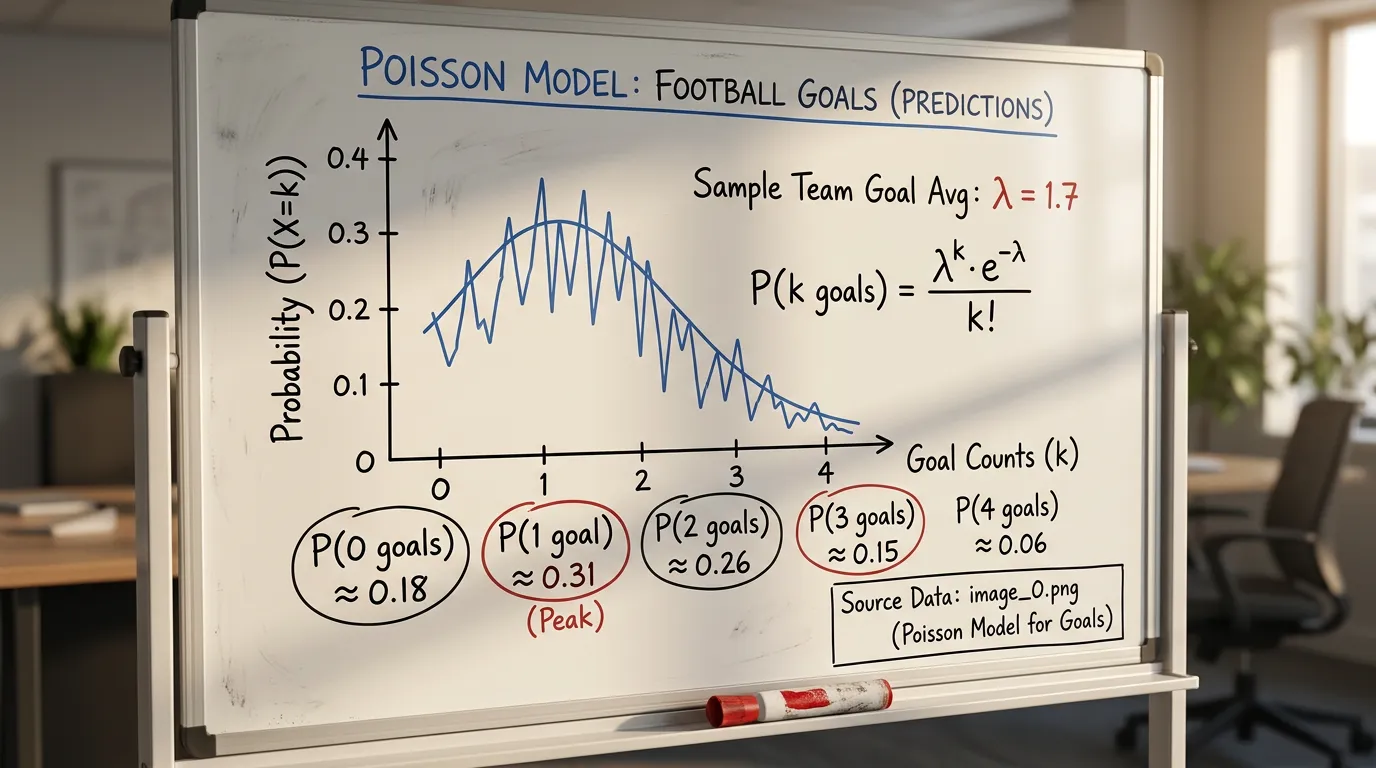
Poisson-fordelingen svarer på ét spørgsmål: hvis noget sker i gennemsnit λ gange i en given periode, hvad er så sandsynligheden for, at det sker præcis k gange? Formlen er P(k) = (λ^k × e^(−λ)) / k!, hvor e er Eulers tal (cirka 2,718) og k! er fakultet. Det ser afskrækkende ud, men det er faktisk én regneoperation i et regneark — i Excel hedder funktionen POISSON.DIST. Sæt λ ind, sæt k ind, få sandsynlighed ud.
Hvorfor virker det på fodbold? Fordi mål er relativt sjældne. I Superligaen 2024/25 blev der scoret 406 mål i grundspillet — 3,08 pr. kamp — det højeste gennemsnit siden 2002/03. Men selv 3 mål pr. kamp er “sjældent” i den forstand, Poisson forudsætter: mål kan falde når som helst, de er statistisk uafhængige nok af hinanden, og det gennemsnitlige antal kan estimeres fra historisk data. De fleste akademiske fodbold-analyser af Poisson bekræfter, at fordelingen rammer virkelige Superliga-resultater inden for få procents fejl.
Der er selvfølgelig undtagelser. Meget høje scoringskampe (5-4, 6-3) og meget lave (0-0, 1-0) følger ikke Poisson helt lige så elegant, fordi fodbold har psykologi — et hold, der fører 3-0, holder ofte igen, og et hold, der er bagud, kaster hele opstillingen frem. Det giver en mild klumpeeffekt, som avancerede modeller håndterer med korrektioner som Dixon-Coles-justering. Til de fleste praktiske formål er den rene Poisson-model dog god nok. Jeg har kørt den i flere år på danske og europæiske markeder og opdager sjældent, at korrektionerne flytter beslutningen — de strammer kun præcisionen med få procentpoint.
Angrebs- og forsvarsstyrke — byggeklodserne i din model
Her skiller jeg begynderes modeller fra fungerende modeller. Mange nybegyndere tager bare gennemsnittet af holdets mål pr. kamp og bruger det som λ. Det virker ikke. Et hold scorer ikke lige mange mål mod alle modstandere. FC København laver flere mål hjemme mod Fredericia end ude mod FC Midtjylland. Modellen skal tage højde for både angribende og forsvarende styrke — for begge hold.
Den praktiske metode: du beregner fire værdier pr. hold. Hjemme-angrebsstyrke (hvor mange mål scorer holdet hjemme i forhold til liga-gennemsnittet), hjemme-forsvarsstyrke (hvor få mål lukker de ind hjemme i forhold til gennemsnittet), ude-angrebsstyrke og ude-forsvarsstyrke. Liga-gennemsnittet i Superligaen 2024/25 har ligget på cirka 1,54 mål pr. hold pr. kamp. Et hold, der scorer 2,0 mål hjemme i gennemsnit, har en hjemme-angrebsstyrke på 2,0 / 1,54 = 1,30. Et hold, der lukker 1,0 ind hjemme i gennemsnit, har en hjemme-forsvarsstyrke på 1,0 / 1,54 = 0,65 (lavere tal er bedre forsvar).
Det er her, bevægelsen i Superligaen 2024/25 bliver interessant. Det gennemsnitlige skud pr. hold pr. kamp nåede 13,3 — det højeste niveau i de syv sæsoner, hvor tallet er blevet registreret. Skud på mål landede på 4,61. Når den samlede skudvolumen stiger, og når skudkvaliteten (målt i xG) samtidig når rekord, oversættes det direkte til Poisson-parameteren: λ-værdierne for hele ligaen rykker opad, og det er en af grundene til, at over/under 2,5-markeder har set flere justeringer end normalt hen over sæsonen.
Hvor meget historisk data skal du bruge? Jeg anbefaler mindst de seneste 15-20 kampe pr. hold, men du skal veje dem. De seneste 5 kampe siger mere om aktuel form end kampe fra august, selv om de alle er fra samme sæson. En simpel løsning: brug et glidende gennemsnit med højere vægt til de seneste kampe. Avancerede modeller går videre med Bayesian-opdateringer, men for en privatspiller er et vægtet gennemsnit nok.
Beregning af en Superliga-kamp — skridt for skridt
Lad os tage en tænkt kamp. Hjemmeholdet har hjemme-angrebsstyrke 1,20 og hjemme-forsvarsstyrke 0,90. Udeholdet har ude-angrebsstyrke 0,95 og ude-forsvarsstyrke 1,10. Liga-gennemsnit for mål scoret hjemme er 1,60 (hjemmebanefordel inkluderet), og for gæster 1,30. I Superligaen har hjemmeholdet historisk vundet 45-50 procent af kampene og gæsterne 25-30 procent, og gennemsnitligt 1,3-1,5 mål pr. hold pr. kamp — præcis det niveau, vi kalibrerer mod.
Forventet antal mål for hjemmeholdet: 1,60 × 1,20 × 1,10 = 2,11. For udeholdet: 1,30 × 0,95 × 0,90 = 1,11. Det er vores to λ-værdier. Nu kan vi regne sandsynligheder for alle resultater.
Start med at bygge en tabel: hjemmeholdets mål 0 til 5 vandret, udeholdets mål 0 til 5 lodret. I hver celle ganger vi P(hjemme scorer k) × P(ude scorer m) ved hjælp af Poisson-formlen. For eksempel: sandsynligheden for 1-1 bliver P(hjemme = 1 | λ=2,11) × P(ude = 1 | λ=1,11) = 0,2582 × 0,3658 = 0,0945, altså cirka 9,45 procent. Sandsynligheden for 2-1 er P(hjemme = 2) × P(ude = 1) = 0,2724 × 0,3658 = 0,0997, altså 9,97 procent.
Summer cellerne for at få 1X2: alle celler, hvor hjemmeholdet har flere mål end udeholdet, giver hjemmesejr. Diagonalen (samme antal) giver uafgjort. Resten giver udesejr. I vores eksempel falder tallene omkring 54 procent hjemmesejr, 22 procent uafgjort og 24 procent udesejr. Det oversættes til fair odds på 1,85, 4,55 og 4,17. Hvis bookmakeren tilbyder udesejr i 5,00, har du potentielt value — hvis din model vel at mærke er kalibreret ordentligt.
Over/under-totaler er nemme at udregne fra samme tabel. Summer alle celler, hvor samlet mål (k + m) er 0, 1 eller 2, for at få P(under 2,5). Over 2,5 er 1 minus det. I vores eksempel lander fordelingen på cirka 45 procent under 2,5 og 55 procent over 2,5, hvilket svarer til fair odds 2,22 og 1,82. BTTS (begge hold scorer) kommer ud af at summere alle celler, hvor hjemmeholdet og udeholdet begge har mindst 1 mål — i dette eksempel cirka 61 procent, fair odds 1,64.
Den slags beregning tager 20 minutter første gang, du laver den, og 5 minutter, når du har et regneark, der gør det automatisk. Jeg har en skabelon, der kører 30 kampe ad gangen på under et minut. Mit råd: byg selv din første model fra bunden, så du forstår, hvor tallene kommer fra, før du genbruger andres.
Svaghederne ved modellen — det den ikke kan se
Poisson-modellen har blinde vinkler, og det er ærligere at lægge dem åbent frem end at lade dig tro, den er et orakel. Den første er, at modellen antager uafhængighed mellem holdene. Men i fodbold er et mål ofte en reaktion — et bagudstående hold kaster flere folk frem og åbner bagud. Det betyder, at sandsynligheden for “hjemme 3, ude 2” er en smule højere, end modellen forudsiger, mens “hjemme 3, ude 0” er lidt lavere. Dixon-Coles-korrektionen justerer præcis for dette.
Den anden svaghed er modstanders-specifik variation. Modellen bruger gennemsnitlig styrke over en periode og antager, at den er stabil. Hvis et hold har byttet halvdelen af startelleveren om vinteren, er den gamle form ikke længere repræsentativ. Modellen vil give forkerte λ-værdier, og det er så dit job at justere manuelt eller at begrænse data til kampe spillet af den aktuelle trup.
Tredje svaghed: ekstreme kampe. Et hold, der skal undgå nedrykning på sidste spilledag, spiller ikke som et gennemsnit. En derby-kamp har indbygget taktisk forsigtighed, som drukner gennemsnitstal. Jeg anvender Poisson som et udgangspunkt, men jeg tager altid et subjektivt tjek af kontekst — kampe, hvor jeg ikke tror på modellen, spiller jeg simpelthen ikke, uanset hvor “værdi” tallene viser.
Der er også et principielt problem: hvis mange professionelle spillere bruger Poisson-lignende modeller, er markedet allerede blevet effektiviseret for de mest oplagte forskelle mellem markeds-odds og Poisson-odds. Din edge bliver derfor lille, og den opstår primært i nicher, hvor data er sjælden eller sent opdateret. Poisson er et basisværktøj, ikke et gyldent ticket — og den bedste effekt får du ved at kombinere den med markedsovervågning og med værdi-beregninger, som vores gennemgang af værdibud-metoden udfolder mere dybdegående. Hele den analytiske ramme for fodbold-væddemål er samlet i den samlede bet tips-guide for Superligaen.
Hvornår modellen virkelig tjener sin plads
Jeg bruger Poisson mest på to typer markeder. Første: korrekte score på mellem-odds (3-1, 2-0, 1-1), hvor bookmakerne ofte har brede marginer, og hvor små forskelle i λ-værdier kan flytte fair odds betydeligt. Anden: over/under-markeder i kampe, hvor der er markant forskel mellem to holds tempo og defensive stabilitet. Begge er tilfælde, hvor en beregnet sandsynlighedsfordeling giver dig en meget mere nuanceret pris end markedets sum af udfald.
Hvor jeg ikke bruger Poisson: 1X2 på tunge favorit-kampe, hvor margin er lav, og hvor markedsinformationen er dyb. Der slår lukkelinen min model for ofte, til at jeg tjener på at afvige. Og i live-betting, hvor informationsstrømmen er for hurtig til, at en statisk model kan følge med. Modellen er et pre-match-værktøj, og den trives, når du har timer til at analysere før kickoff.
Hvor præcis er Poisson-modellen på Superliga-kampe?
På 1X2-udfald rammer en kalibreret Poisson-model typisk inden for 2-4 procentpoint af de faktiske langsigtede fordelinger — godt nok til at finde value, men ikke et orakel. På korrekte score er præcisionen lavere på lavfrekvente resultater (4-3, 0-4), og det er netop i midten af fordelingen (1-1, 2-1, 1-0), at modellen giver sin bedste edge.
Hvilke data skal jeg bruge for at estimere angrebsstyrke?
De seneste 15-20 kampe pr. hold er et fornuftigt minimum. Vægt de seneste kampe højere end de ældre, og adskil hjemme- og udestatistik. Hvis et hold har skiftet træner eller opstilling markant, skal du begrænse data til perioden efter ændringen — ellers modellerer du et hold, der ikke længere eksisterer.
Skabt af redaktionen på ”bet Tips Fodbold”.